人工智慧(artificial intelligence, AI)指能模擬或複製人類智慧的一種技術,開發這種技術使電腦能夠像人一樣思考、學習、解決問題和做出決策,人類智慧的行為諸如模仿、學習、思考、判斷以及啟發等,因此人工智慧是一種理念、目的或是框架,可以囊括諸多概念與方法。人工智慧可以分為多個子領域,每個子領域都專注於不同的問題和技術,在人工智慧的基礎下誕生了許多諸如資料探勘(data mining)、機器學習(machine learning)以及深度學習(deep learning)等概念及方法,這些人工智慧方法彼此相關聯,目標皆為讓機器擁有部分於人類智慧相似的能力。
Artificial Intelligence (AI) refers to a technology that simulates or replicates human intelligence, enabling computers to think, learn, solve problems, and make decisions like humans. AI involves behaviors such as imitation, learning, reasoning, judgment, and inspiration. Therefore, AI can be viewed as a concept, a goal, or a framework that encompasses various ideas and methods. AI can be divided into several subfields, each focusing on different problems and techniques. Concepts and methods such as data mining, machine learning, and deep learning have emerged based on the foundation of AI. These AI methods are interrelated and aim to provide machines with human-like cognitive abilities.
資料探勘方法透過各種不同方法來挖掘原本大量且複雜的資料,目的在給定的資料中挖掘知識、特徵或關係。資料探勘方法包含了許多種機器學習方法與深度學習方法,只要是基於大量資料中分析的方法都能稱作為資料探勘方法。機器學習是在已處理過的資料中透過學習已知的特徵來對新事物進行分析或預測,機器學習在進行學習前必須給定一組已由人類知識萃取出特徵並整理後的資料。
Data mining techniques utilize various methods to extract knowledge, features, or relationships from complex and massive datasets. It encompasses a range of machine learning and deep learning methods. Any approach that analyzes large datasets can be referred to as data mining. Machine learning involves analyzing or predicting new data based on known features extracted from pre-processed data. Before learning, machine learning requires a set of data that has been labeled and organized with features extracted from human knowledge.
而深度學習基於神經網路(neural network)理論,不同於機器學習方法,深度學習大幅減少需先由人類知識來做的知識萃取,而是以大量的神經元建構相當複雜的神經網路,並從大量資料中讓多層結構的神經網路學習資料中隱含的特徵為何,對資料進行學習前僅需少量人類知識的介入。神經網路是由多個神經元組成的數學模型,這些神經元模擬了人腦神經元之間的連接,神經網絡通常包括輸入層、隱藏層和輸出層,其中隱藏層的數量和結構可以根據任務需求來調整,之所以稱為深度學習就是因為它的神經網絡通常包含數十到數百個隱藏層(早期受限於硬體設備,類神經網路的隱藏層往往不達十層),累積的神經元數量可高達數百萬個,這種深度結構允許神經網絡學習從數據中提取不同層次的特徵,有助於更好地理解和處理大規模、高維度的數據以及複雜的任務,當然它所需要的訓練數據就相當大量。人工智慧模型的訓練(training)過程就如同物理模型的率定(calibration)過程,透過研究人員將深度學習模型的目標物標籤(labeling)提供給模型,通常會透過梯度下降法這類的最佳化方法,讓預測與實際結果間的誤差最小,逐漸調整模型的參數和權重,最後獲得一個最佳化的深度學習模型,因此,通常深度學習模型在訓練階段是耗時、耗計算資源的,但在執行時則是快速的,這也是為何近期Nvidia的AI晶片非常受歡迎,因為它的設計與環境可以加速模型的訓練。
Deep learning, on the other hand, is based on neural network theory and differs from traditional machine learning methods by significantly reducing the need for human-knowledge-based feature extraction. It constructs complex neural networks using a large number of neurons and learns the hidden features within massive datasets through multi-layer neural network structures, requiring minimal human intervention before data learning. Neural networks are mathematical models composed of multiple neurons, simulating connections between human brain neurons. Typically, a neural network consists of an input layer, hidden layers, and an output layer, with the number and structure of hidden layers adjustable according to the task requirements. The term "deep learning" refers to the fact that such networks often contain dozens to hundreds of hidden layers (earlier constrained by hardware, neural networks rarely had more than ten layers), with accumulated neuron counts reaching millions. This deep structure allows neural networks to learn and extract hierarchical features from data, facilitating better understanding and handling of large-scale, high-dimensional data and complex tasks. Naturally, such networks require vast amounts of training data.
The training process of AI models is akin to the calibration process in physical modeling, where researchers use optimization methods like gradient descent to minimize errors between predicted and actual results by adjusting model parameters and weights. As a result, the training phase of deep learning models is often time-consuming and computationally intensive, but they perform quickly during execution. This is one reason why Nvidia’s AI chips are so popular recently, as their design and environment can accelerate model training.
人工智慧透過觀察和分析數據後,可以自動識別、找出規律和趨勢,並使用這些知識來做出預測、決策和解決問題,欲學習的問題本身需存在某些潛在規則可以去學習,並且有明確的目標,存在ㄧ定規則卻目前並無理論公式可描述,因此才須利用機器學習或深度學習來解決問題。而機器學習以及深度學習中提到的學習,指的是觀察一組資料並發掘資料中潛在知識的過程,學習的類型又可分成三類,監督式學習(supervised learning)給定一組資料包含要判斷或預測的答案給機器進行學習、非監督式學習(unsupervised learning)給定一組資料但不包含要判斷或預測的答案來讓機器學習對資料進行分群或是組織以及強化式學習(reinforcement learning)則是機器會不斷地嘗試錯誤(trial-and-error)並針對潛在的正確答案得到回饋。而近年因電腦計算能力增強,對於利用資料探勘、機器學習以及深度學習的研究層出不窮,讓深度學習衍生出各式各樣的功能,深度學習已經運用在非常多個領域,包括圖像識別、語音識別、自然語言處理、自動駕駛、醫學影像分析、金融領域等。例如自然語言處理(natural language processing, NLP)則專注在使電腦能理解、生成和處理人類自然語言的領域,涵蓋語言模型、文本分析、機器翻譯等方面;強化學習(reinforcement learning)透過試誤法來訓練代理(如機器人或遊戲玩家)以達到最佳化某對象為目標;電腦視覺(computer vision)致力於使計算機能夠理解和解釋視覺資訊,含括照片和影片的分析、物件偵測和場景理解等。
After observing and analyzing data, AI can automatically identify patterns and trends and use this knowledge to make predictions, decisions, and solve problems. The problem to be learned must have inherent patterns to be discovered and a clear objective that is difficult to describe using theoretical formulas, making machine learning or deep learning necessary for problem-solving. The learning process in machine learning and deep learning refers to discovering latent knowledge by observing a dataset. Learning can be classified into three types: supervised learning, which involves providing a dataset containing answers to be predicted or identified for the machine to learn; unsupervised learning, which involves providing a dataset without predefined answers to allow the machine to perform clustering or organization; and reinforcement learning, where the machine continuously tries and errors and receives feedback based on potential correct answers.
With the increase in computing power in recent years, research using data mining, machine learning, and deep learning has become increasingly prevalent, leading to the development of various functions derived from deep learning. Deep learning has been applied in numerous fields, including image recognition, speech recognition, natural language processing, autonomous driving, medical image analysis, and finance. For example, natural language processing (NLP) focuses on enabling computers to understand, generate, and process human natural language, covering areas such as language modeling, text analysis, and machine translation. Reinforcement learning trains agents (such as robots or game players) to optimize specific objectives through trial and error. Computer vision strives to enable computers to understand and interpret visual information, encompassing image and video analysis, object detection, and scene understanding.
多類別物件分類與偵測(multiple object classification and detection)是電腦視覺領域常見的任務之一,可以做到如影像分類(image classification)來判斷影像中有幾種物件,也可以做到如物件定位(object localization)可以判斷影像中的物件還能定位物件在畫面中的位置。而人工智慧技術在電腦視覺領域的成效能歸功於深度學習方法中的卷積神經網路(convolutional neural network, CNN)的發展,CNN能夠有效地在影像中提取二維特徵,分析特徵來推論影像中的內容。然而,使用CNN僅能進行影像分類任務,無法將所有的物件辨認出來並且標示物件在畫面中的位置(例如用矩形框標示)。因此,根據CNN的理論基礎,有研究提出R-CNN(Region-CNN)深度學習方法,透過在影像中劃分出多個候選區域(region proposal),對每個候選區域進行卷積過程,判斷畫面中的物件位置與類別。R-CNN的推出奠定了深度學習方法在物件偵測任務上的基礎,同樣R-CNN的研究團隊很快地推出了更新版本的Fast R-CNN,加入RoI池化層(region of interest pooling),將每個候選區域先進行池化再卷積,得到固定尺寸的特徵圖,能減少運算過程並且保留影像特徵,提升運算速度。有研究認為Fast R-CNN的運算速度還能再提高,推出Faster R-CNN,加入區域提取網路(region proposal network, RPN)來取代原先Fast R-CNN劃分出候選區域的方式,將這些網路產生的候選區域稱為錨(anchors),將候選區域的選擇、影像特徵的提取以及物件分類與定位等任務設計成同個網路架構來訓練,有效減少運算時間並提升速度。
Multi-object classification and detection is a common task in the field of computer vision, capable of tasks such as image classification to identify the number of objects in an image or object localization to determine the position of objects within an image. The success of AI technology in computer vision can be attributed to the development of convolutional neural networks (CNNs) within deep learning methods. CNNs can efficiently extract two-dimensional features from images and use these features to infer image content. However, CNNs can only perform image classification tasks and cannot identify and localize all objects in the image (such as marking them with bounding boxes). Therefore, based on the theoretical foundation of CNNs, researchers proposed the R-CNN (Region-CNN) deep learning method, which divides an image into multiple candidate regions (region proposals) and performs convolution on each region to determine the location and class of objects in the image.
The introduction of R-CNN laid the groundwork for deep learning methods in object detection tasks. The same research team quickly introduced an updated version, Fast R-CNN, which added the Region of Interest (RoI) pooling layer to pool each candidate region before convolution, obtaining fixed-size feature maps, reducing computation time while preserving image features and improving processing speed. Researchers believed that the computation speed of Fast R-CNN could be further improved, leading to the introduction of Faster R-CNN, which incorporated a Region Proposal Network (RPN) to replace the original method of generating candidate regions in Fast R-CNN. The candidate regions produced by this network were referred to as anchors, and the task of selecting candidate regions, extracting image features, and object classification and localization were designed into a single network architecture for training, effectively reducing computation time and increasing speed.
雖然R-CNN的出現奠定了物件偵測深度學習方法的基礎,但有研究認為如R-CNN這種兩階段學習方法(two-stage learning)在運算效率提升上較難以突破,因此,推出YOLO(you only look once)演算法,強調其運算效率,將物件位置偵測與辨識視為單一的回歸問題,從影像輸入到輸出結果僅依靠一個神經網路來運算,在訓練時將整張影像作為學習的目標,YOLO演算法在訓練與辨識時,對同張影像僅「看」一次,即其命名的由來。另外,同樣為一階段學習方法的SSD(single shot multibox detector)演算法,也是將物件位置偵測與物件類別辨識合併成一個神經網路就可以完成所有的多物件分類與偵測任務,SSD採用整個CNN網路進行位置偵測與辨識,並且運算時提取不同尺度的特徵圖,強化在大或小物件上的辨識效果。多物件分類與偵測深度學習方法發展初期,以上述三種演算法蔚為主流,在準確性與運算效率上各有優劣,在相同的應用任務下,Faster R-CNN通常可以獲得較高準確性的結果,但運算效率遠不及其他兩種演算法,YOLO與SSD皆能以即時運算速度高效運算,其中SSD又比YOLO快一些,但YOLO演算法以較佳的辨識準確性佔優。
Although the introduction of R-CNN established the foundation for deep learning methods in object detection, researchers found that two-stage learning methods like R-CNN were challenging to improve in terms of computational efficiency. Consequently, the YOLO (You Only Look Once) algorithm was introduced, emphasizing computational efficiency by viewing object localization and recognition as a single regression problem. From image input to output, a single neural network is used for computation. During training, the entire image is used as the learning target, and the YOLO algorithm processes each image only once, hence its name. Similarly, the SSD (Single Shot MultiBox Detector) algorithm, also a single-stage learning method, combines object localization and classification into a single neural network capable of completing all multi-object classification and detection tasks. SSD employs an entire CNN network for localization and recognition, extracting feature maps at different scales to enhance recognition performance for large and small objects.
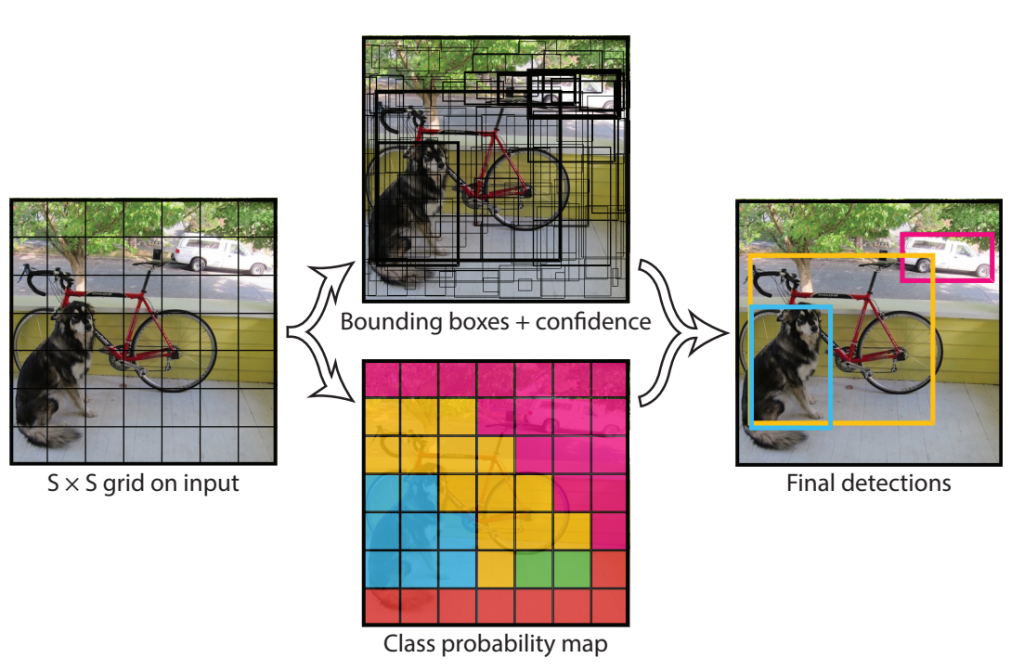
YOLO演算法將物件偵測與分類的任務整合到單一的網路中,稱為統一偵測(unified detection)。其工作原理是先將影像劃分成多個網格,然後針對每個網格中的資訊進行運算,從整張影像中提取特徵並辨識物件。這樣的網路結構可從整張影像中提取特徵,並且用來辨識目標物,同時在整張影像上針對不同的目標物以邊界框標示其位置與類別。這使得網路可以分析整張影像的特徵,維持一定的辨識能力並提高辨識速度。在YOLO演算法中,影像被劃分成𝑆×𝑆的網格。如果目標物的中心位於某個網格內,則此網格負責此目標物的偵測。每個網格可輸出𝐵個邊界框及其各自的信心分數(confidence score)。
In the early stages of multi-object classification and detection deep learning methods, the aforementioned three algorithms were dominant, each with its strengths and weaknesses in terms of accuracy and computational efficiency. For the same application task, Faster R-CNN typically achieved higher accuracy but was far less efficient than the other two algorithms. Both YOLO and SSD could operate with real-time processing speed, with SSD being slightly faster but YOLO achieving better recognition accuracy.
The YOLO algorithm integrates object detection and classification into a single network, known as unified detection. Its working principle is to first divide the image into multiple grids and then process the information in each grid, extracting features and recognizing objects from the entire image. This network structure extracts features from the whole image, recognizes target objects, and simultaneously marks their locations and categories in the image using bounding boxes. This allows the network to analyze features from the entire image, maintaining recognition capability and improving recognition speed. In the YOLO algorithm, the image is divided into an S×S grid. If the center of an object is within a particular grid, that grid is responsible for detecting that object. Each grid outputs B bounding boxes and their respective confidence scores.
YOLO利用單個卷積神經網路架構建置辨識模型來進行多物件偵測與辨識,YOLO的神經網路架構由最一開始的卷積層負責從輸入影像中提取特徵,完全連接層則負責輸出目標物的類別與邊界框的機率與座標。YOLO受到GoogLeNet模型的啟發,網路結構中包含24層卷積層以及2個全連接層,不同之處在於YOLO簡單地使用1*1的縮減層(reduction layers)與3*3的卷積層取代GoogLeNet所使用的Inception模組。全連接層會輸出每一個包含目標物的邊界框類別機率與其座標位置,YOLO將輸出邊界框的長與寬針對整張影像的長與寬正規化到0至1的範圍,邊界框的中心點座標也同時正規化到0至1的範圍。而在各個神經網路層的啟動函數中,除了在最後一層使用線性啟動函數(linear activation function)外,其餘皆使用洩漏ReLU啟動函數(leaky ReLU activation function)。
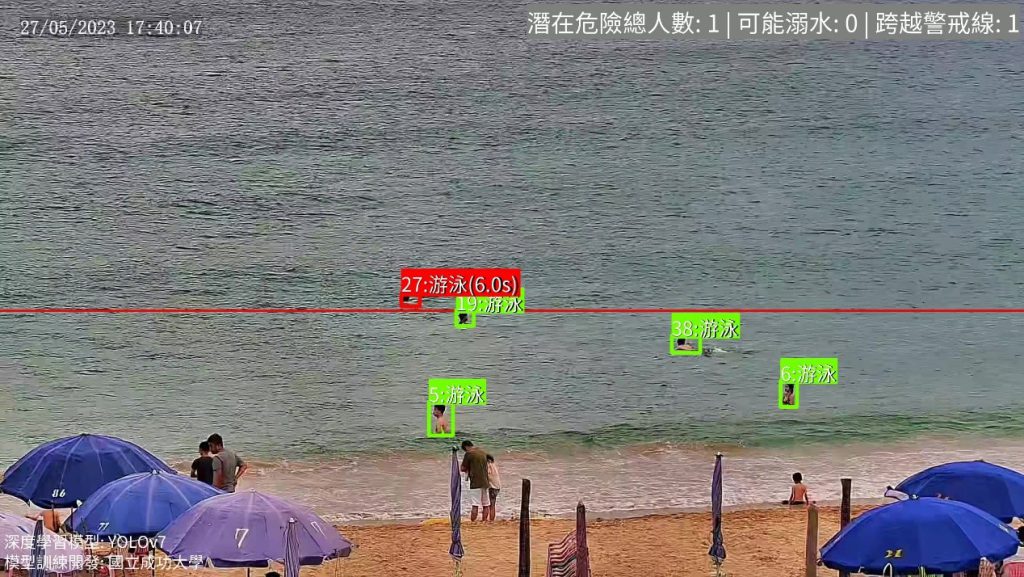
物件偵測深度學習方法在訓練時,是透過不斷迭代訓練調整內部參數,嘗試降低模型的誤差直到最佳,因此計算誤差的方式會影響模型的訓練效果,即計算誤差的損失函數(loss function)十分重要。YOLO演算法自問世以來,已經推出了多個版本,近期以YOLOv7為廣泛使用,無論是在訓練過程與實際使用上都表現出高度的穩定性與準確性。此外,YOLOv7的開發團隊還無償提供了開源且易於修改的程式碼,可以根據計畫的不同需求進行靈活修改。台南市的智慧海灘偵測系統亦是使用YOLOv7演算法來建置,讓AI學習如何辨識海域遊憩活動與海灘上的民眾,也能學習如何辨識可能發生溺水的民眾,甚至學習離岸流發生時的特徵。
YOLO uses a single convolutional neural network architecture to construct a recognition model for multi-object detection and recognition. The YOLO network structure consists of 24 convolutional layers and two fully connected layers. Unlike GoogLeNet, which uses the Inception module, YOLO simply employs 1×1 reduction layers and 3×3 convolutional layers. The fully connected layers output the class probabilities and coordinates for each object bounding box, with the bounding box's width and height normalized to the image dimensions between 0 and 1. The center coordinates of the bounding box are also normalized to the range of 0 to 1. In the activation functions for each neural network layer, all except the last layer use the leaky ReLU activation function, while the last layer uses a linear activation function.
During the training of object detection deep learning methods, the internal parameters are iteratively adjusted to minimize the model's error until it is optimized. Thus, the method for calculating errors, the loss function, is crucial to the model's training effectiveness. Since its introduction, the YOLO algorithm has released multiple versions, with YOLOv7 being widely used recently. It demonstrates high stability and accuracy in both training and practical use. Additionally, the YOLOv7 development team has provided open-source and easily modifiable code, allowing flexible adjustments according to the needs of different projects. The smart beach detection system in Tainan City also uses the YOLOv7 algorithm, enabling AI to learn how to identify recreational activities and people on the beach, as well as potentially recognizing drowning individuals and detecting features of rip currents.